


Immer mehr KI-Bots besiedeln das Internet, durchsuchen Websites und nutzen die Inhalte, um die Bot-Modelle zu trainieren. Wer das nicht möchte, kann versuchen, Bots zu sperren.
Auch wenn es einfach klingt, KI-Bots zu sperren, ist das in der Praxis oft schwierig und mit Kosten verbunden. Ich werde einige Methoden vorstellen, die in der Praxis eingesetzt werden, und ihre Effektivität erklären.
Methode 1: robots.txt
Der erste Schritt führt natürlich gleich zur robots.txt-Datei, die im Root-Verzeichnis jeder Website liegen sollte. In dieser Datei sind Regeln festgelegt, wie sich Bots auf der Website verhalten sollen und welche Inhalte oder Bereiche für sie gesperrt sind.
Die großen Bots von Google, Bing und vielen anderen lesen die robots.txt-Datei vor dem Crawlen und prüfen, was ihnen nicht gestattet ist.
Aber funktioniert das auch für KI-Bots?
Zunächst einmal kann es nicht schaden, den Inhalt der robots.txt um die folgenden Inhalte zu erweitern, um den großen KI-Bots schon einmal den Zugriff auf die Website einzuschränken:
User-agent: GPTBot
Disallow: /
User-agent: Google-Extended
Disallow: /
User-agent: ClaudeBot
Disallow: /
User-agent: Amazonbot
Disallow: /Es ist einfach, aber wie wirkungsvoll ist es?
Ich würde mich nicht auf einen großen Erfolg verlassen, da die Regeln in der robots.txt freiwillig sind. Das heißt, die Bots müssen sich nicht daran halten, wenn sie nicht möchten.
Ich würde diese Methode wohl eher als nutzlos bezeichnen, da sich ein Großteil der KI-Bots ganz sicher nicht an irgendwelche freiwilligen Regeln einer Website hält. Außerdem gibt es hunderte Bots, denen die robots.txt völlig egal ist.
Methode 2: Meta-Tags
Weiterhin besteht die Möglichkeit, eine Seitenregel durch Meta Tags umzusetzen. Dazu muss in die entsprechenden Seiten oder in jede Seite der Website ein Meta Tag eingefügt werden, das sich speziell an die KI-Bots richtet und ungefähr so aussehen kann:
<meta name="robots" content="noai, noimageai, nosnippet">Dies verbietet die Nutzung der Seite ausdrücklich für KI-Zwecke, für die Bildgenerierung und auch für die Erstellung von Snippets. An dieser Stelle muss ich darauf hinweisen, dass Googlebot und andere diese Regelung dahingehend verstehen, dass sie keine Snippets von der Seite in den Suchergebnissen anzeigen dürfen.
Es sollte sich um diese Art von Snippets handeln, die beispielsweise bei Google eingeblendet werden, um schnelle Antworten zu geben und dabei die Quellseite zu verlinken:
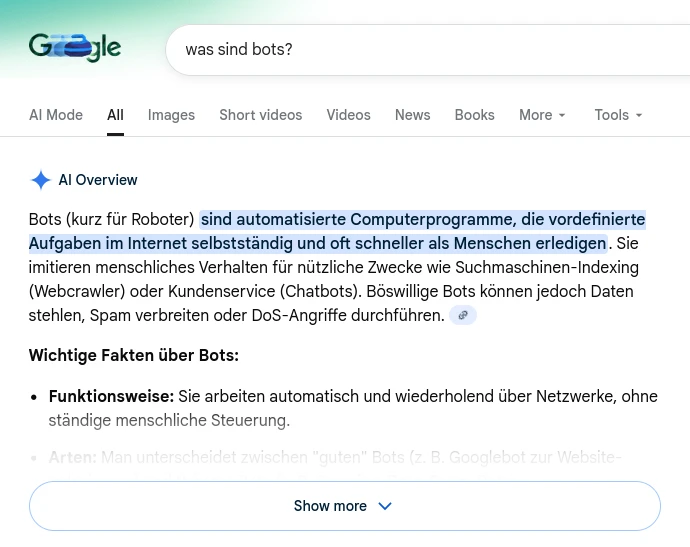
Das würde also bedeuten, dass die Seite an Sichtbarkeit verlieren könnte. Wer unbedingt die volle Sichtbarkeit bei Google und anderen Suchmaschinen erreichen will, sollte das Meta-Tag von oben wohl besser nicht nutzen.
Methode 3: CDN und CAPTCHA
Die letzte Methode, die am effektivsten bei der Beseitigung von Bot-Traffic auf der Website ist, besteht darin, die Bots auf DNS-Level oder durch CAPTCHA auszusperren.
Das ist mit Abstand der beste Weg, um jeglichen Bot-Traffic auf der Website zu reduzieren.
Anbieter wie Cloudflare, Fastly oder Akamai verfügen über Technologien, die auf Grundlage bekannter Bot-IP-Adressen entscheiden können, ob ein Besucher auf der Website eher ein Mensch oder ein Bot ist.
Wenn es sich um einen Bot handelt, wird zusätzlich geprüft, ob es sich um einen guten oder eher bösen Bot handelt. Das bedeutet, dass Bots einer Suchmaschine in der Regel passieren können. Alle anderen werden entweder ganz geblockt oder müssen ein CAPTCHA lösen, das für Bots schwer zu lösen ist.
Fazit
Bot-Traffic war schon immer ein großes Problem. Bots durchsuchen das Internet, stehlen Inhalte und personenbezogene Daten wie E-Mail-Adressen, Postadressen oder einfach Namen, um Listen zu erstellen und diese auf dem Schwarzmarkt zu verkaufen.
Hinzu kommen jetzt die KI-Bots, die fröhlich durch das Internet surfen und Textinhalte und Bilder fetchen, um damit die KI-Technologien zu verbessern.
Dies sollte bei vielen Websitebetreibern Unbehagen hervorrufen. Sie können versuchen, die Methoden von oben umzusetzen, um die Bots in die Schranken zu weisen. Besonders effektiv ist die Methode über DNS und CAPTCHA. Diese Funktionen stehen jedoch in der Regel nur zahlenden Kunden zur Verfügung.
Bei Cloudflare kostet der Spaß rund $10, bei anderen ist er teilweise sehr viel teurer!
Indem man die Bots gezielt aussperrt, hilft man, den Schaden durch KI-generierte Texte im Internet einzudämmen, auch wenn man dafür ein paar Euro im Monat bezahlen muss.